// Put stores the key and value in the database.func(b*Bitcask)Put(key,value[]byte)error{// 1. 校验iflen(key)==0{returnErrEmptyKey}ifb.config.MaxKeySize>0&&uint32(len(key))>b.config.MaxKeySize{returnErrKeyTooLarge}ifb.config.MaxValueSize>0&&uint64(len(value))>b.config.MaxValueSize{returnErrValueTooLarge}// 2. 上锁b.mu.Lock()deferb.mu.Unlock()// 3. 写入datafileoffset,n,err:=b.put(key,value)iferr!=nil{returnerr}// 4. 落盘ifb.config.Sync{iferr:=b.curr.Sync();err!=nil{returnerr}}// in case of successful `put`, IndexUpToDate will be always be falseb.metadata.IndexUpToDate=false// 5. 更新meta信息ifoldItem,found:=b.trie.Search(key);found{b.metadata.ReclaimableSpace+=oldItem.(internal.Item).Size}// 6. 更新 key -> {fileId, offset, size} 索引信息item:=internal.Item{FileID:b.curr.FileID(),Offset:offset,Size:n}b.trie.Insert(key,item)returnnil}
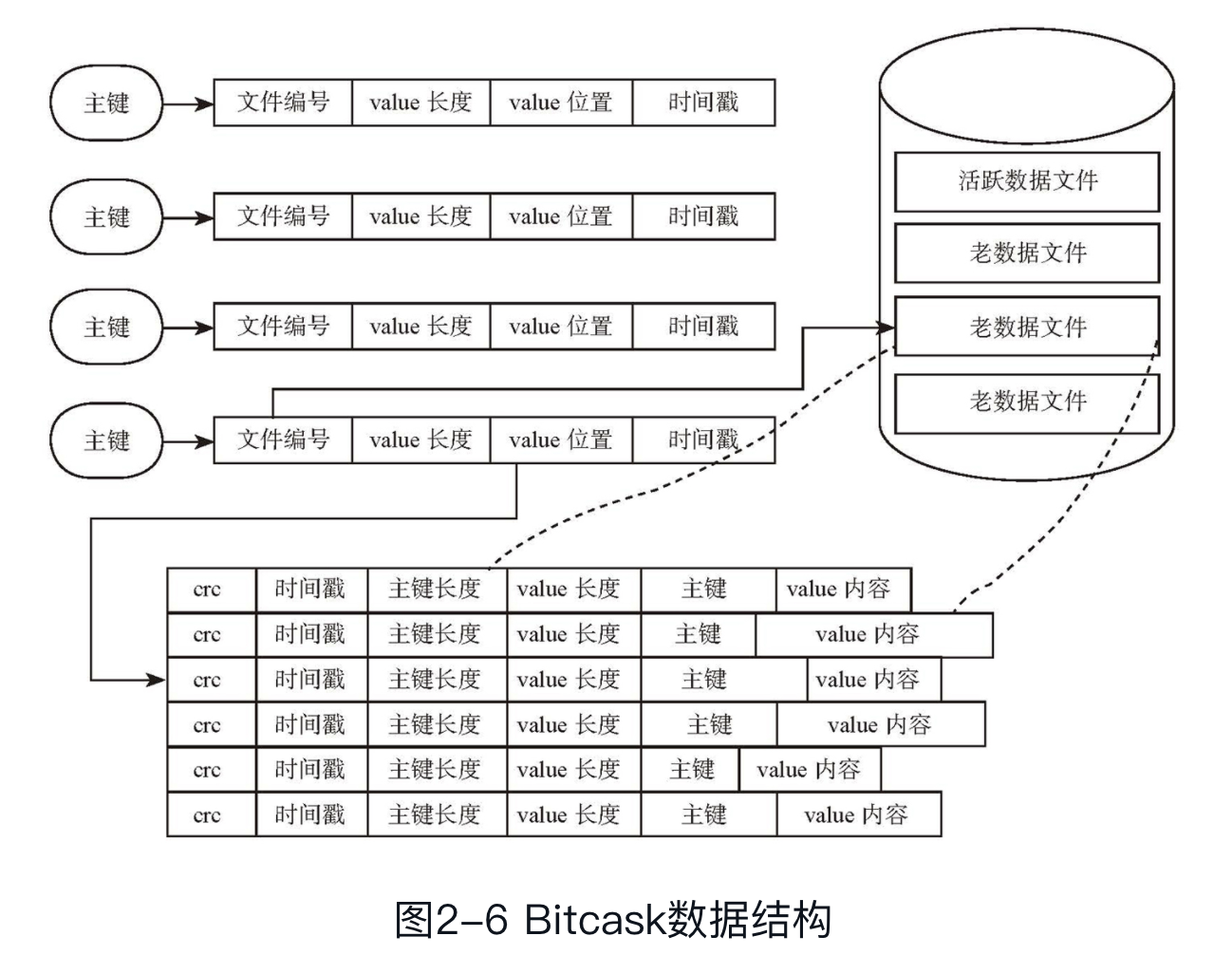
// Get fetches value for a keyfunc(b*Bitcask)Get(key[]byte)([]byte,error){b.mu.RLock()deferb.mu.RUnlock()e,err:=b.get(key)iferr!=nil{returnnil,err}returne.Value,nil}// get retrieves the value of the given keyfunc(b*Bitcask)get(key[]byte)(internal.Entry,error){vardfdata.Datafile// 1. 寻找key对应的index信息value,found:=b.trie.Search(key)if!found{returninternal.Entry{},ErrKeyNotFound}// 2. 判断过期ifb.isExpired(key){returninternal.Entry{},ErrKeyExpired}// 3. 找到对应的文件页item:=value.(internal.Item)ifitem.FileID==b.curr.FileID(){df=b.curr}else{df=b.datafiles[item.FileID]}// 4. 根据offset和size读取对象e,err:=df.ReadAt(item.Offset,item.Size)iferr!=nil{returninternal.Entry{},err}// 5. 校验编码是否发生问题checksum:=crc32.ChecksumIEEE(e.Value)ifchecksum!=e.Checksum{returninternal.Entry{},ErrChecksumFailed}returne,nil}
// 根据内存中的indexr的所有key,重新开一个新的db,然后写进去// Merge merges all datafiles in the database. Old keys are squashed// and deleted keys removes. Duplicate key/value pairs are also removed.// Call this function periodically to reclaim disk space.func(b*Bitcask)Merge()error{// 1. 判断是否在 IsMerging阶段(感觉用atomic更好些)b.mu.Lock()ifb.isMerging{b.mu.Unlock()returnErrMergeInProgress}b.isMerging=trueb.mu.Unlock()deferfunc(){b.isMerging=false}()b.mu.RLock()err:=b.closeCurrentFile()iferr!=nil{b.mu.RUnlock()returnerr}// 2. 读取所有的dataFileIds,从小到大排序filesToMerge:=make([]int,0,len(b.datafiles))fork:=rangeb.datafiles{filesToMerge=append(filesToMerge,k)}err=b.openNewWritableFile()iferr!=nil{b.mu.RUnlock()returnerr}b.mu.RUnlock()sort.Ints(filesToMerge)// 3. 开临时目录 merge,执行完会删除该目录// Temporary merged database pathtemp,err:=ioutil.TempDir(b.path,"merge")iferr!=nil{returnerr}deferos.RemoveAll(temp)// 4. 新开一个db// Create a merged databasemdb,err:=Open(temp,withConfig(b.config))iferr!=nil{returnerr}// 5. 根据内存中的 trie(也就是索引),重新将数据从老db读取,并写入到新db中// Rewrite all key/value pairs into merged database// Doing this automatically strips deleted keys and// old key/value pairserr=b.Fold(func(key[]byte)error{item,_:=b.trie.Search(key)// if key was updated after start of merge operation, nothing to doifitem.(internal.Item).FileID>filesToMerge[len(filesToMerge)-1]{returnnil}e,err:=b.get(key)iferr!=nil{returnerr}ife.Expiry!=nil{iferr:=mdb.PutWithTTL(key,e.Value,time.Until(*e.Expiry));err!=nil{returnerr}}else{iferr:=mdb.Put(key,e.Value);err!=nil{returnerr}}returnnil})iferr!=nil{returnerr}iferr=mdb.Close();err!=nil{returnerr}// no reads and writes till we reopenb.mu.Lock()deferb.mu.Unlock()iferr=b.close();err!=nil{returnerr}// 6. 删除现有的文件// Remove data filesfiles,err:=ioutil.ReadDir(b.path)iferr!=nil{returnerr}for_,file:=rangefiles{iffile.IsDir()||file.Name()==lockfile{continue}ids,err:=internal.ParseIds([]string{file.Name()})iferr!=nil{returnerr}// if datafile was created after start of merge, skipiflen(ids)>0&&ids[0]>filesToMerge[len(filesToMerge)-1]{continue}err=os.RemoveAll(path.Join(b.path,file.Name()))iferr!=nil{returnerr}}// 7. 将新文件更名// Rename all merged data filesfiles,err=ioutil.ReadDir(mdb.path)iferr!=nil{returnerr}for_,file:=rangefiles{// see #225iffile.Name()==lockfile{continue}err:=os.Rename(path.Join([]string{mdb.path,file.Name()}...),path.Join([]string{b.path,file.Name()}...),)iferr!=nil{returnerr}}b.metadata.ReclaimableSpace=0// 8. 根据文件内容,重新load到内存数据// And finally reopen the databasereturnb.reopen()}